
Every now and then, people ask about the advantages of using Netlify before a traditional cloud provider’s file storage service. Cloud providers can serve static files from your own domain name, so why use something else? In fact, Netlify uses those services to store files too. The difference is in the value added by Netlify on top of those services.
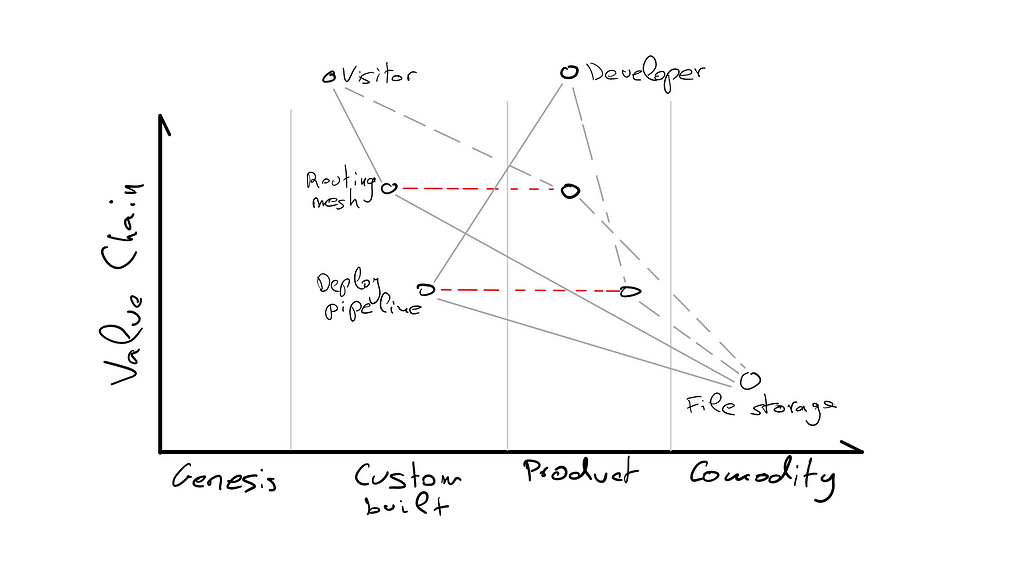
If we were going to look at this difference on a map, we’d say that file storage is a commodity. Storage costs are very low, which turns those services into utilities. Anyone can take several files and upload them to the cloud. This presents us with some opportunities that we’re going to explore.
The first one is about what to show your visitors when they use different domains and subdomains. For instance, I want to show specific content for www.example.com and beta.example.com. This is usually solved by custom solutions. You can make that work with the right combination of DNS records and storage buckets.
Another interesting opportunity is efficient file uploads. Off the shelf tools usually upload all your files to a storage bucket every time you run them, even if there are files that have not changed. It makes this process slower than it should be if they only uploaded the files that have changed. This was one key advantage for Dropbox. Their desktop clients knew how to manage files to save bandwidth and time.
Off the shelf tools don’t offer bucket integrity either. If two visitors request the same file while you’re updating your bucket’s content, they can get different content. If that content requires new CSS and JavaScript, your visitors won’t see what you expect them to see. You can work around this with the right combination of CDN caching, expiration headers, and scripts to expire the cache after each upload.
Netlify solves these problems for you, and many others. We’ve created a real product from the experience of implementing those custom built solutions ourselves. The rest of this post explains some infrastructure details behind Netlify’s deploying and routing mesh.
We’ve built Netlify’s core around Merkle trees, the same structures used in Git, ZFS file systems, and blockchain technology. A Merkle tree is a structure where each node is labeled with the cryptographic hash of the labels of all the nodes under it.
As you read earlier, we use cloud file storage to persist content. But, we use content addressable references rather than file names as identifiers. We don’t store files with the name jquery-3–31.js , we hash its content and we use that as the file name. This gives strong guarantees that we serve the same content regardless the file name. We don’t care if it’s named jquery-3–31.js and you decide to rename it later to jquery-3-latest-download.js. Each deploy calculates those hashes and generates a new tree based on the content that changed, and content that we already have stored. If you only change one file, we will only upload one file. If you rename a file, we will create a new node in the tree with that file name, without upload its content. If you remove a file, we won’t reference it in the new tree. That also means that each deploy is immutable. We always serve the contents of the same tree under a domain. When we finish processing new deploys, we only swap the tree to serve. Having immutable trees also prevents us from showing mixed content.
These immutable guarantees are also the base for many other features. The first one is atomic and instant rollbacks. As Murphy said, if something can go wrong, it will go wrong at some point. Immutability doesn’t prevent you from publishing content with broken markup, and content that you publish on accident. Since your previous deploy was never modified, we can revert to that state at any time. We only need to change the tree reference where your domain points again.
Another interesting advantage of immutable deploys is that we can point any name you want to any content you want. This is the base for what we call Deploy Previews and Branch Deploys. Given a set of changes in a Git branch, a DNS subdomain entry, and some basic routing rules, it’s not hard to route traffic to a specific tree in a safe and reliable way. We can serve different content in beta.example.com and www.example.com by pointing each domain to a different tree. We can also build on top of these primitives to implement new features, like Split Testing at the edge by Git branch.
These are the foundations of why Netlify is different than using a cloud provider’s file service. We’ve taken an opportunity that those commodity services offer to build an awesome product.
If you’re excited about web and infrastructure engineering, we’re always looking to grow our team.
How Netlify’s deploying and routing infrastructure works was originally published in Netlify on Medium, where people are continuing the conversation by highlighting and responding to this story.